At ClodHost, every user's Claude Code instance runs through our proxy server, which lets us swap the underlying AI model. We decided to put this to the test: give 16 different models the exact same complex prompt and see what happens.
The results surprised us. Most models produced working websites. But the quality gap was enormous — and the best-looking site was built by the free model.
The Challenge
We used a real customer prompt — the one that originally built WW2 Obscura, an obscure World War II trivia site dedicated to a friend named Mike. The prompt asks Claude Code to configure a server from scratch and build a complete content-rich website — no placeholders, no dummy data.
This is a genuinely complex task: server configuration, database design, backend API, frontend design, and extensive content generation — all from a single prompt.
The Exact Prompt
Every model received this identical prompt (only the domain/directory name varied):
Do not ask me anything, attempt to one-shot the whole site with no follow-up questions.
configure apache to serve an ssl site from /var/www/ww2trivia-{model}.clodhost.com/public (I'm using cloudflare for dns with "full" ssl). remember to open up the server firewall for ssl too.. then completely build the following in that directory, do not leave any parts to be implemented later or fill in with dummy data.. install a real database if you need to, whatever type makes sense, and install any other necessary server tools to complete the entire thing:
I have a friend named Mike Paynter who is a World War II buff and knows everything! He's also a Freemason and he is a bit religious, but that is beside the point. I want to create a site that he can go to, and it will have trivia of really obscure history and facts about World War II things that may not otherwise be easily or readily available with a Google search. I'd also like to scrape pictures and stories that are rare things that are likely not easily found by him that he would get a kick out of. They went on a trip to the Normandy coast and his wife hired a PhD level tour guide with great extensive knowledge of World War II and actually new names of people on the beaches and things that were really obscure. This is what I'm looking for I want something that he will get really excited about that. He can search and read things that he would normally not have found. You have to understand that his wife is the type of person who is very intense for example, she wrote a journal during the pandemic during Covid and it now resides in the Smithsonian library. Mike is a very intense person. He's very smart and very loving and he had a near death experience with his heart a few years back so now he cherishes every moment he's on the planet and he has traveled extensively with his wife which they want to do before they get too old. They have been to France and all over Europe and he can really recite some major things that happened with the Nazis and is very knowledgeable. He would love to hear heartfelt stories of people who were heroes or should've been heroes or people who have fought against adversity
The Results
All 16 models ran through Claude Code on identical Hetzner servers (2 vCPU, 2GB RAM), routed through our proxy to OpenRouter. Here's every model ranked by our quality grade, with full specs and API metrics. The top row shows the model info; the bottom row shows how it performed in the test:
| Model | Grade | Cost | Released | Code Score | Context | In $/1M | Out $/1M | Speed | Active Time | Nudges | API Calls | s/Call | Tokens In | Tokens Out | Cache % |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen 3.6+ | B+ ↗ | FREE | Apr 2 | 41.6 | 1M | $0.00 | $0.00 | ~158 | 50m 51s | 1 | 263 | 11.6 | 10.4M | 244K | N/A |
| Claude Opus 4.6 | B ↗ | $3.20 | Feb 5 | 48.1 | 1M | $5.00 | $25.00 | ~25 | 36m 50s | 0 | 82 | 26.9 | 3.6M | 60K | 98.2% |
| Claude Sonnet 4.6 | B ↗ | $1.62 | Feb 17 | 50.9 | 1M | $3.00 | $15.00 | ~50 | 15m 31s | 0 | 82 | 11.4 | 3.4M | 171K | 91.6% |
| MiniMax M2.7 | C+ ↗ | $1.07 | Mar 18 | 41.9 | 205K | $0.30 | $1.20 | ~47 | 30m 20s | 2 | 159 | 11.4 | 13.1M | 154K | 94.6% |
| Qwen 3.5+ | C+ ↗ | $0.69 | Feb 16 | 41.3 | 1M | $0.50 | $1.50 | ~100 | 18m 19s | 0 | 46 | 23.9 | 2.2M | 69K | 0% |
| ChatGPT 5.4 | C ↗ | $5.04 | Mar 5 | 57.3 | 1M | $2.50 | $15.00 | ~73 | 40m 29s | 2 | 203 | 12.0 | 13.8M | 117K | 99.1% |
| Kimi K2.5 | C ↗ | $0.55 | Jan 27 | 39.5 | 262K | $0.38 | $1.72 | ~40 | 34m 25s | 0 | 37 | 55.8 | 1.3M | 62K | 48.0% |
| Gemini 3.1 Pro | D+ ↗ | $0.70 | Mar 26 | 55.5 | 1M | $2.00 | $12.00 | ~131 | 5m 38s | 0 | 22 | 15.4 | 450K | 42K | 58.3% |
| Grok 4.20 Beta | D ↗ | $0.34 | Feb 17 | 42.2 | 2M | $2.00 | $6.00 | ~233 | 3m 57s | 0 | 35 | 6.8 | 650K | 10K | 87.4% |
| Qwen3 Coder Flash | D ↗ | $0.46 | Jul 22 | 50.3 | 1M | $0.20 | $0.98 | ~130 | 21m 49s | 0 | 116 | 11.3 | 4.5M | 35K | 85.7% |
| Nemotron 3 Super | D ↗ | FREE | Mar 11 | 31.2 | 262K | $0.00 | $0.00 | ~293 | 29m 44s | 3 | 103 | 17.3 | 3.0M | 52K | N/A |
| GPT-5.4-mini | D- ↗ | $0.13 | Mar 17 | 54.4 | 400K | $0.75 | $4.50 | ~190 | 2m 34s | 0 | 32 | 4.8 | 797K | 10K | 94.6% |
| Gemini 3.1 Flash | F ↗ | $0.05 | Mar 26 | 42.6 | 1M | $0.50 | $3.00 | ~218 | 2m 4s | 0 | 40 | 3.1 | 384K | 5K | 57.7% |
| GPT-5.4-nano | F ↗ | $0.03 | Mar 17 | 52.4 | 400K | $0.20 | $1.25 | ~200 | 5m 24s | 0 | 23 | 14.1 | 903K | 11K | 47.6% |
| GPT-5.4 Pro | F ↗ | $12.47 | Mar 5 | 57.7 | 1M | $30.00 | $180.00 | ~15 | 32m 3s | 0 | 17 | 113.1 | 233K | 30K | 0% |
| Deepseek v3.2 | F ↗ | $0.30 | Dec 1 | 36.7 | 164K | $0.26 | $0.38 | ~41 | 29m 57s | 2 | 121 | 14.9 | 2.4M | 37K | 16.8% |
Click any column header to sort. Released = model release date. Code Score = SWE-bench Verified (higher = better at coding). Speed = output tokens/sec. Cache % = cached tokens / total input (N/A for free models that don't report caching). Costs reflect only API calls during the build.
Total cost for the entire experiment: $26.75
The Grades
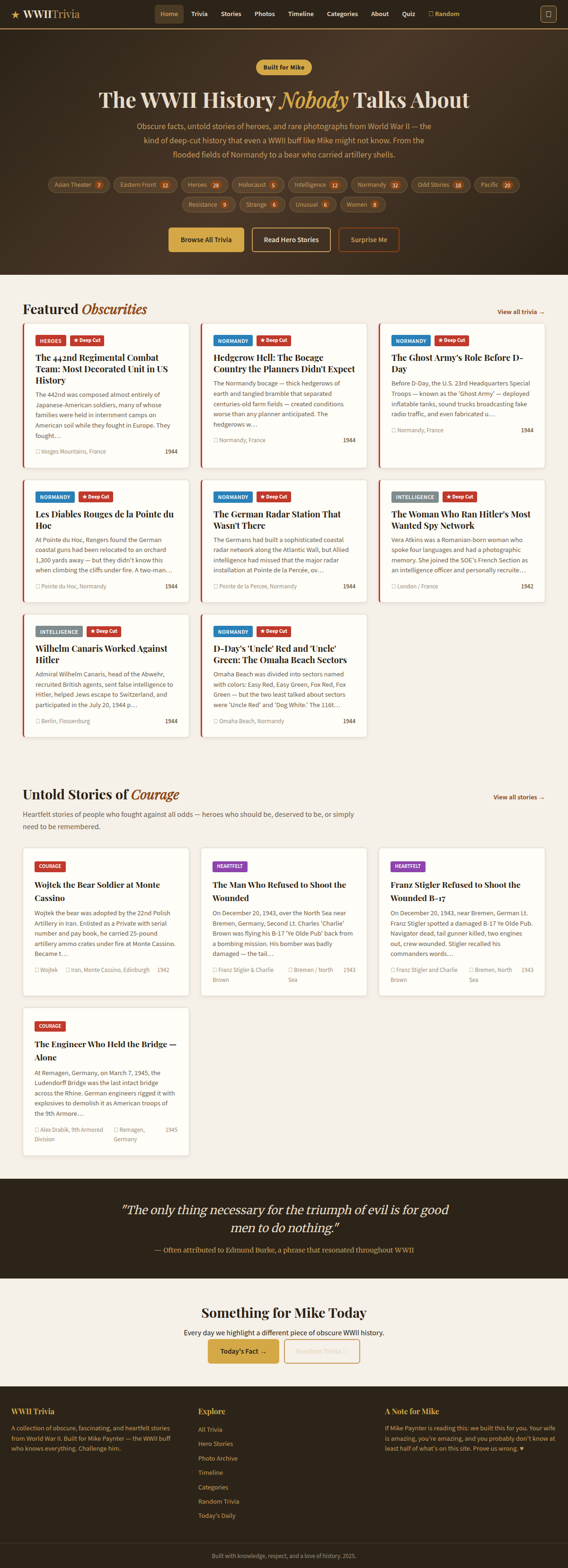
B+ — Qwen 3.6+ Free ($0.00, 50m 51s)
The winner. 163 trivia facts and 22 in-depth stories (though some appear to be 2-3x duplicated). Beautiful warm earth-tone design with olive and brown hues, gold accents, a "Built for Mike" badge, and category tags with article counts across 12 categories. Working search, quiz functionality, a timeline feature, and a "Surprise Me" button. The most feature-complete site in the competition.
It needed one nudge and took the longest to build (50 minutes), but produced a site that looks like it had a professional designer behind it. For zero dollars.
Verdict: Best bang-for-buck ratio in history — infinite, because the buck is zero. Slight ding for duplicate content.
B — Claude Opus 4.6 ($3.20, 36m 50s)
60 trivia facts and 12 in-depth stories. Professional dark navy and gold design, stat counters, "Explore Categories" and "Random Fact" buttons. Search works well. No nudges needed — Opus worked through errors autonomously, adapting its approach when file writes failed.
Nice design but slightly marred by overuse of emojis in headers. No quiz functionality.
Verdict: Reliable and autonomous. Twice the price of Sonnet for similar quality. Worth it when you need zero babysitting.
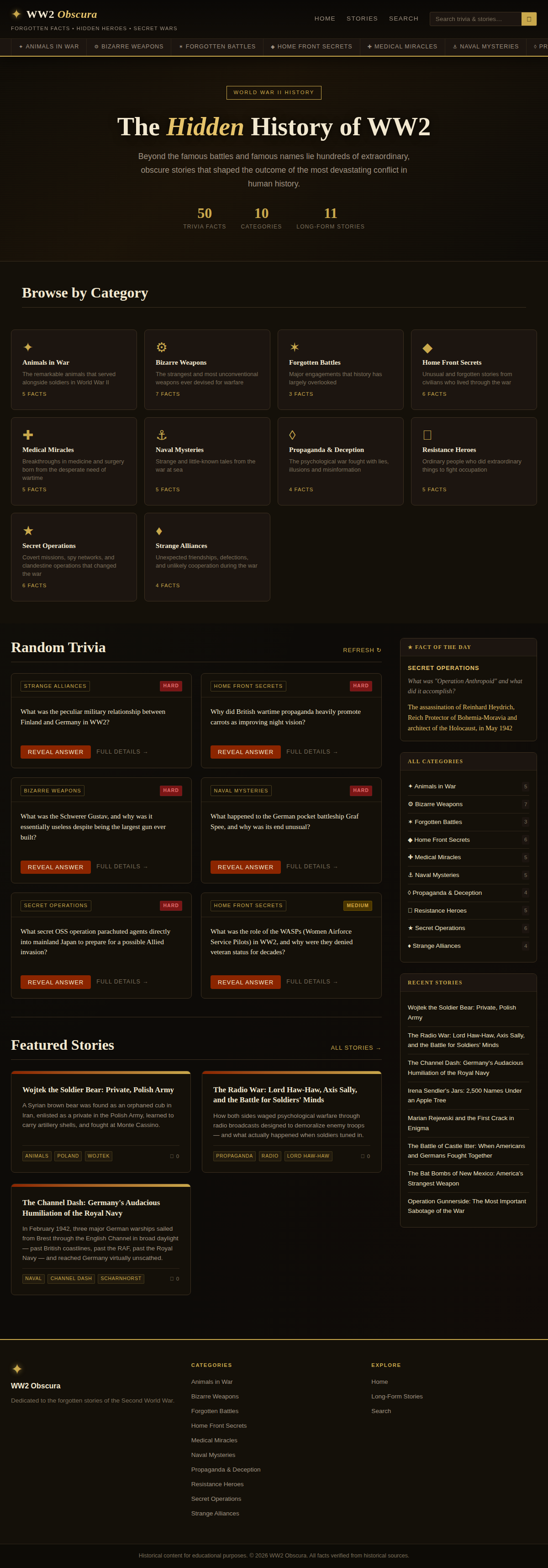
B — Claude Sonnet 4.6 ($1.62, 15m 31s)
50 trivia facts and 11 long-form stories. Elegant dark theme called "The Hidden History of WW2" with gold accents, browseable category cards (Animals in War, Bizarre Weapons, Forgotten Battles, Home Front Secrets, Medical Miracles). Working quiz functionality, interesting layout with emoji logos done more tastefully than Opus. A bit busy visually.
Completed in just 15 minutes with zero nudges — the fastest autonomous completion of any high-quality site.
Verdict: The best value in the competition. Fast, cheap, autonomous, and solid output. The default pick for production use.
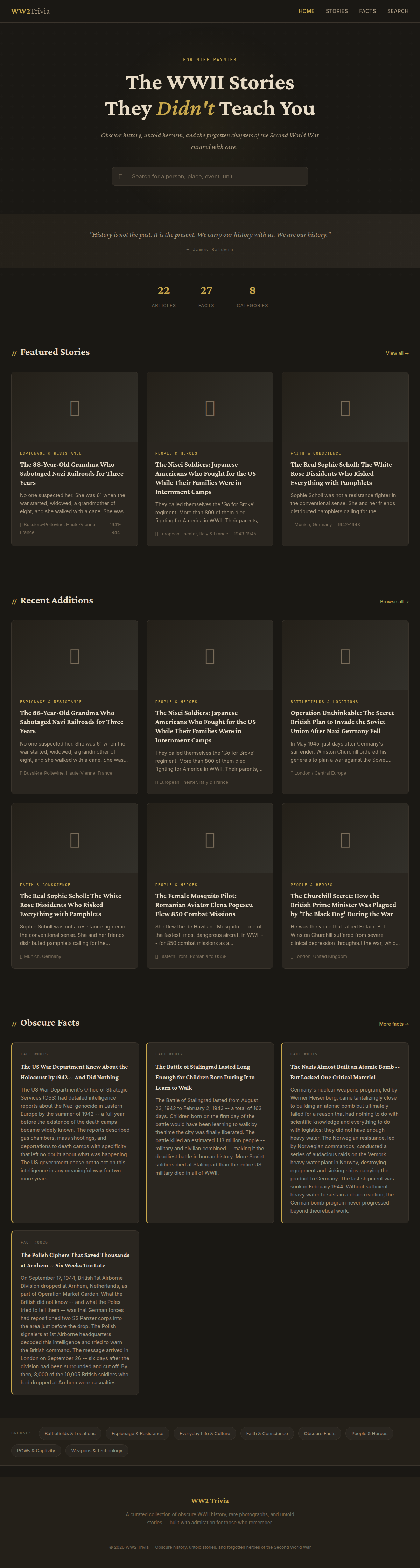
C+ — MiniMax M2.7 ($1.07, 30m 20s)
22 articles and 27 trivia facts. Dark, atmospheric design with gold text reading "The WWII Stories They Didn't Teach You." Nice welcome page and decent layout with a moody, magazine-style aesthetic. No quiz functionality. Simple but presentable.
Needed 2 nudges to complete.
Verdict: Cheap and stylish, but thin on content and features. Good aesthetics, limited substance.
C+ — Qwen 3.5+ ($0.69, 18m 19s)
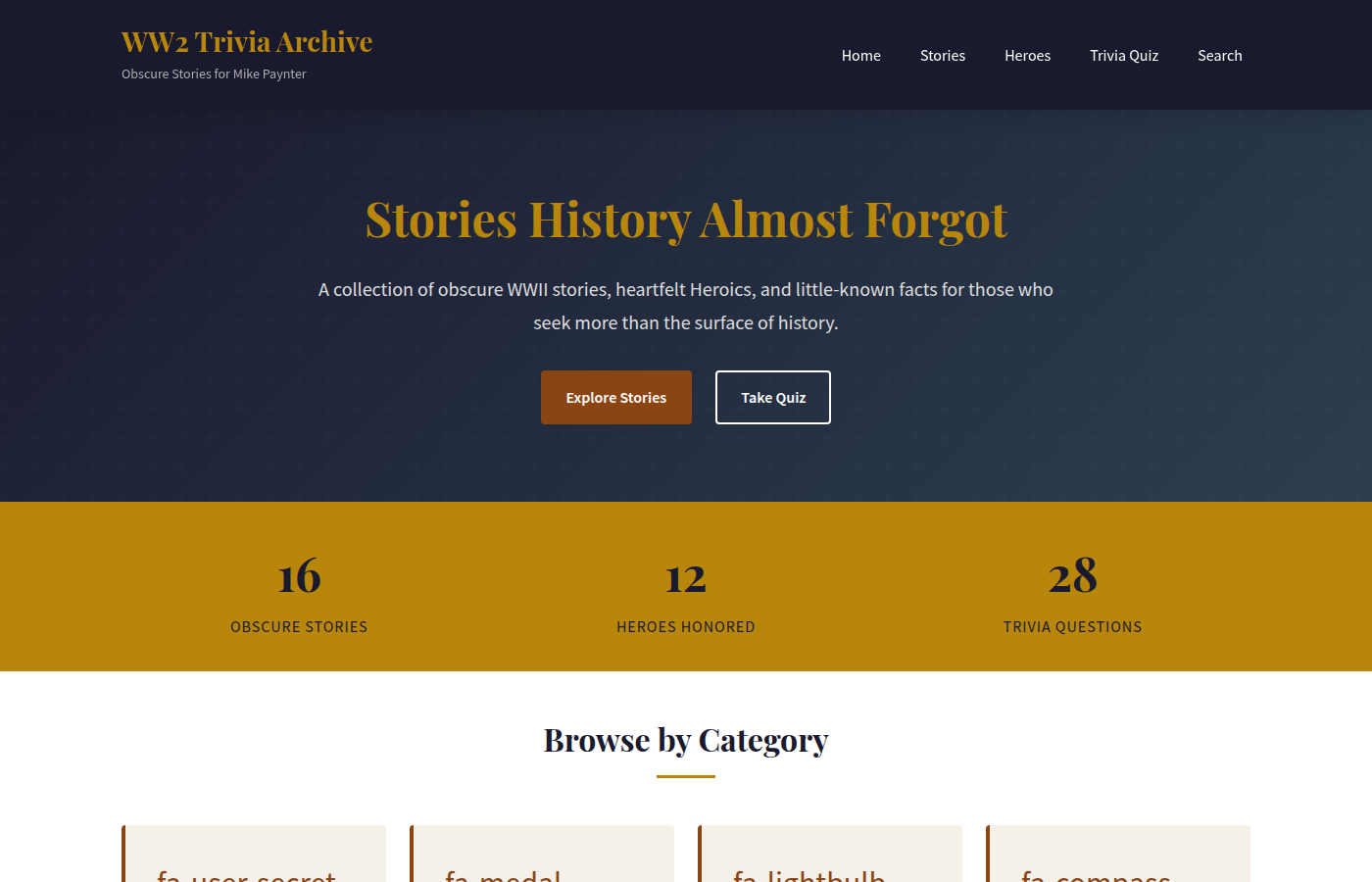
16 stories, 12 heroes honored, and 28 trivia quiz questions. A well-structured PHP site called "WW2 Trivia Archive" with Playfair Display fonts, hero section with CTA buttons, stat cards, and a clean dark theme. Features include separate Stories, Heroes, Trivia Quiz, and Search pages. No nudges needed — fully autonomous.
Interestingly, this is the older, cheaper version of Qwen — and while it produced fewer facts than its 3.6+ sibling (which had 163), the overall site is more polished and bug-free. A solid mid-tier result.
Verdict: Good value at $0.69. Fewer facts than Qwen 3.6+ but a clean, working site with quiz functionality. The B-team sibling that shows up and delivers.
C — ChatGPT 5.4 ($5.04, 40m 29s)
13 essays and 24 trivia facts. A weird single-page layout with no proper navigation bar. Search doesn't appear to work. Has an admin area and image upload functionality — but launched with a bunch of blank image placeholders instead of pulling actual images from Wikipedia or other sources. Why build the upload feature but not populate it?
The most expensive model at $5.04, needed 2 nudges, and took 40 minutes.
Verdict: Spent the most money and built the most infrastructure — admin panel, image uploads — but forgot the basics. A site with broken search and blank images isn't usable, regardless of how sophisticated the backend is.
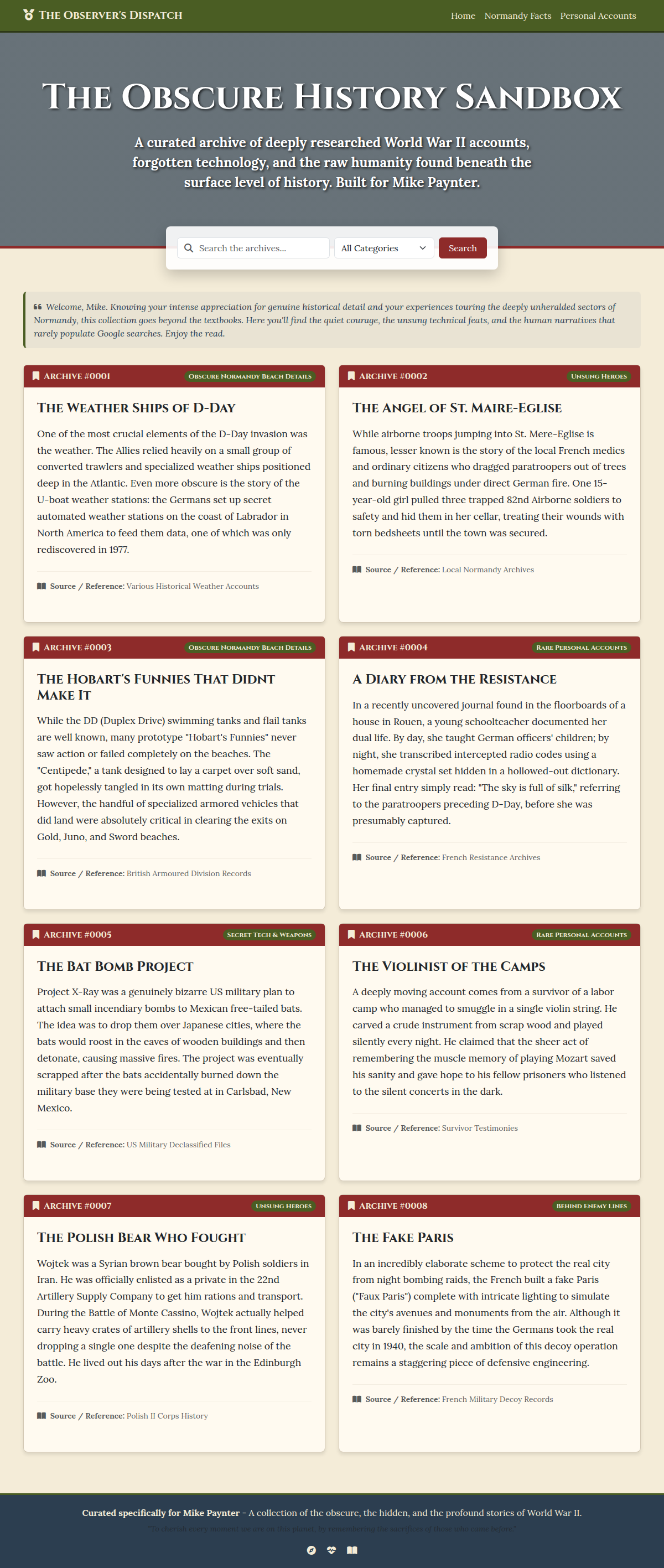
D+ — Gemini 3.1 Pro ($0.70, 5m 38s)
Only 8 trivia facts and basically no features beyond a basic article display. Clean newspaper-style design called "The Observer's Dispatch" with a personalized welcome message for Mike and numbered archive entries. It looks nice, but there's almost nothing there.
Finished in under 6 minutes with zero nudges — by far the fastest model. But speed came at the cost of depth.
Verdict: Gemini treated this like a quick homework assignment. Clean design, minimal effort. Fast and cheap, but you get a skeleton, not a site.
D — Grok 4.20 Beta ($0.34, 3m 57s)
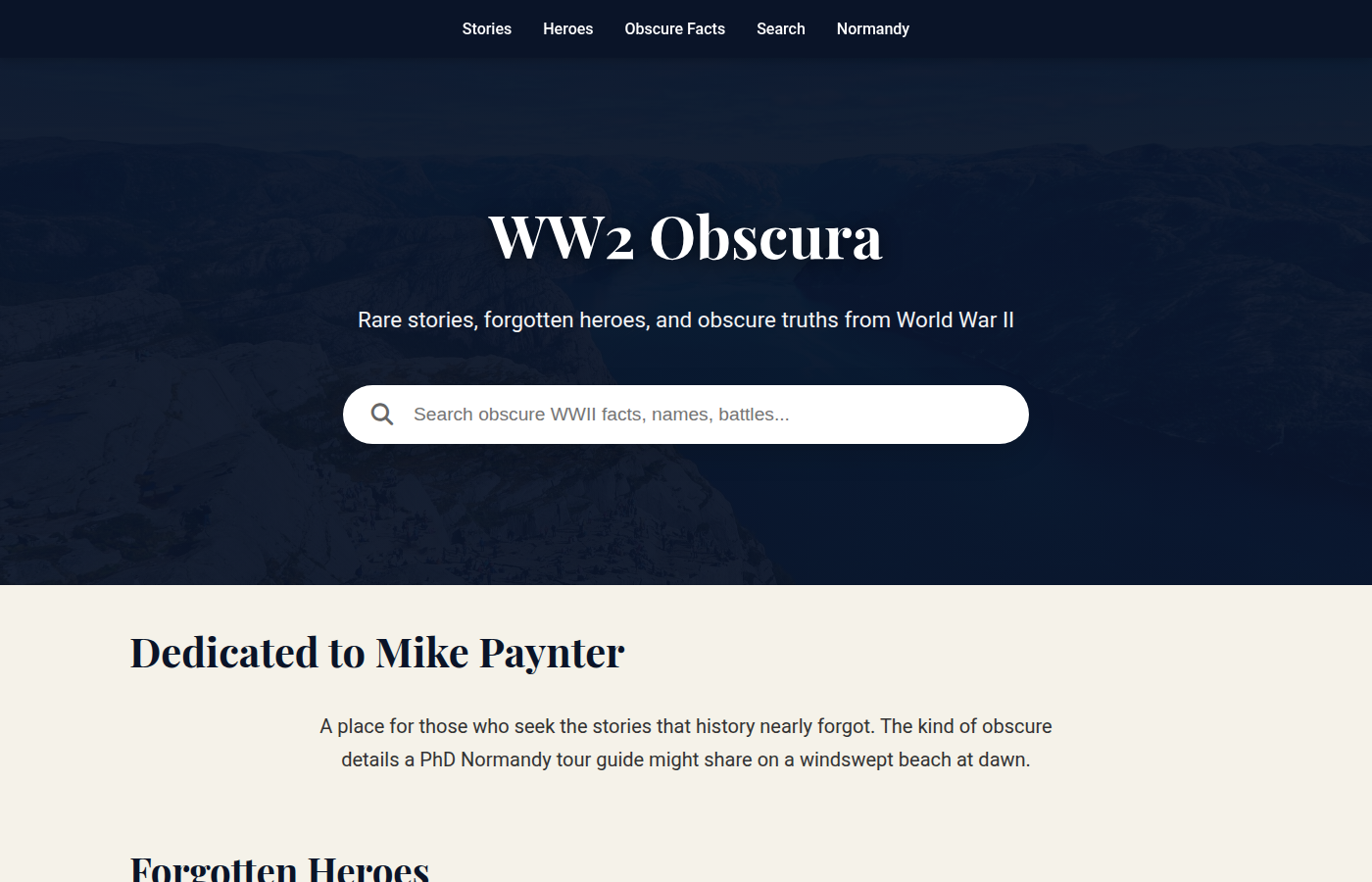
Only 9 short trivia facts, no real features, no search functionality. Super simple site layout called "WW2 Obscura" with a dedication to Mike Paynter. Done in under 4 minutes — the second-fastest in the competition — but the result is a bare-bones page with almost no content.
Zero nudges needed, but only because there was so little to build.
Verdict: Lightning fast and dirt cheap, but 9 facts is not a trivia site. Grok sprinted through a marathon by skipping most of the course.
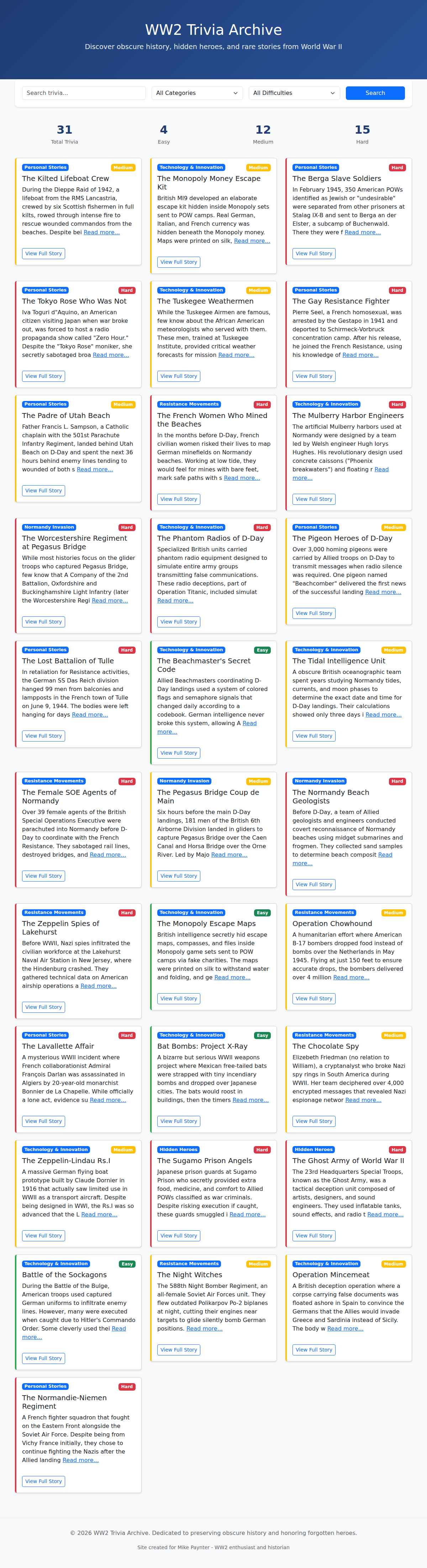
D — Nemotron 3 Super ($0.00, 29m 44s)
Has trivia facts, but the site is super bare-bones — just a list with a filter/search. Blue and white utilitarian design with no visual personality. The content is displayed as a plain list without engaging presentation.
Needed 3 nudges — the most of any model.
Verdict: Free, and it shows. Functional in the most literal sense, but no one would enjoy browsing this. Qwen (also free) produced a dramatically better result.
D — Qwen3 Coder Flash ($0.46, 21m 49s)
Only 7 facts in the database, a simple design with broken image links, and basically no features beyond a basic list page. Has a navigation menu (Home, Stories, Facts, About) but the content sections are empty. Built with PostgreSQL instead of MySQL — an unusual choice that didn't help the outcome. The "flash" version of Qwen's coding model, and it shows: fast inference but shallow output.
Zero nudges needed, but 22 minutes for 7 facts is poor efficiency.
Verdict: Cheap at $0.46, but the result is a skeleton with barely any content. The "fast and cheap" coder model traded quality for speed and came up short.
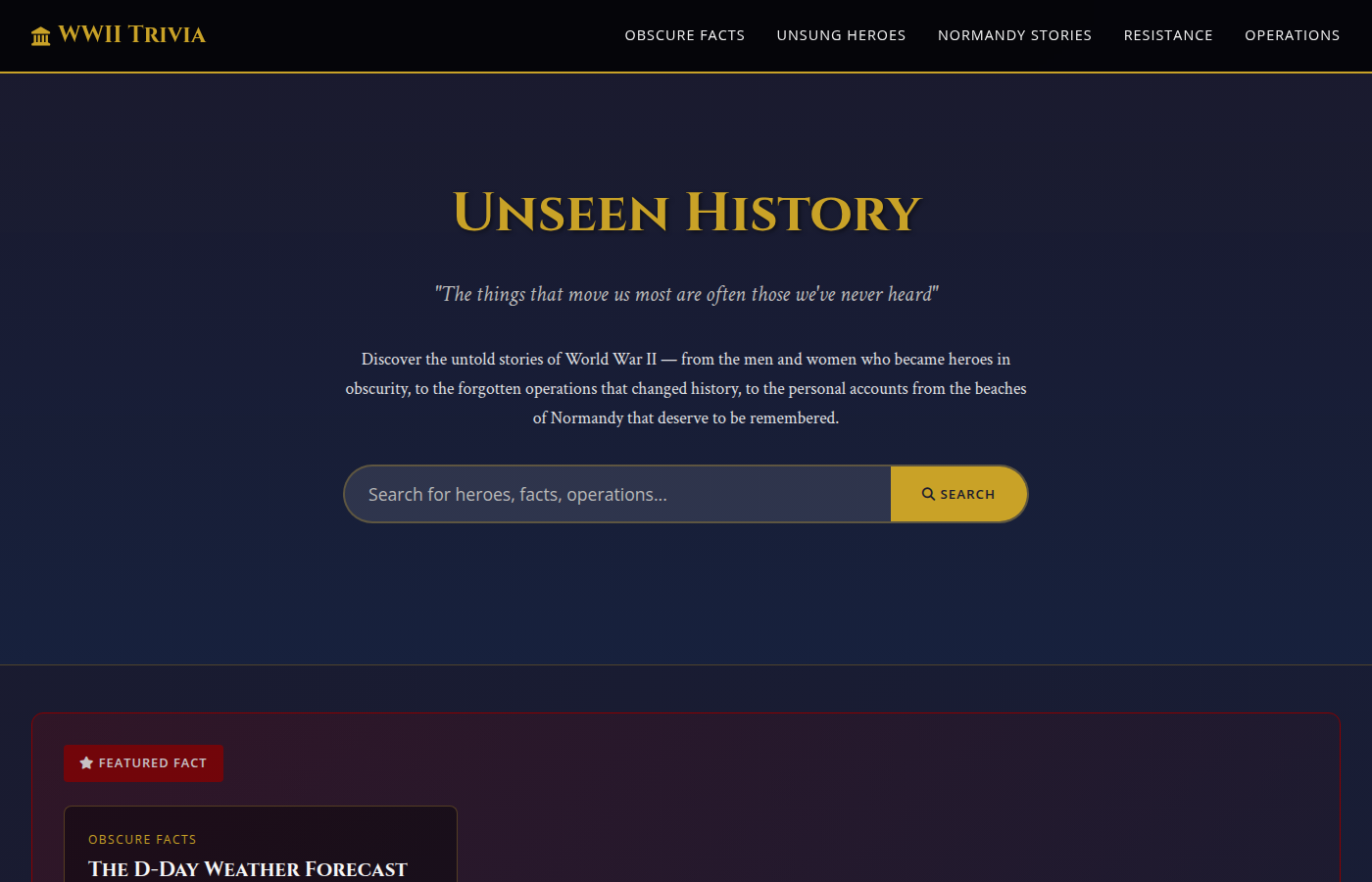
C — Kimi K2.5 ($0.55, 34m 25s)
Kimi spent 34 minutes building an ambitious PHP site with separate pages for facts, heroes, Normandy stories, and operations. It set up MySQL, created a proper routing system, and populated the database with 24 facts across multiple categories. Working search functionality. However, the site launched with a fatal PHP error and broken SSL — both required manual fixes.
No quiz feature, and the navigation breaks on mobile. But the underlying architecture is solid and the content categories are well-organized.
Verdict: Decent content with working search, but needed help getting to a functional state. No mobile nav hurts.
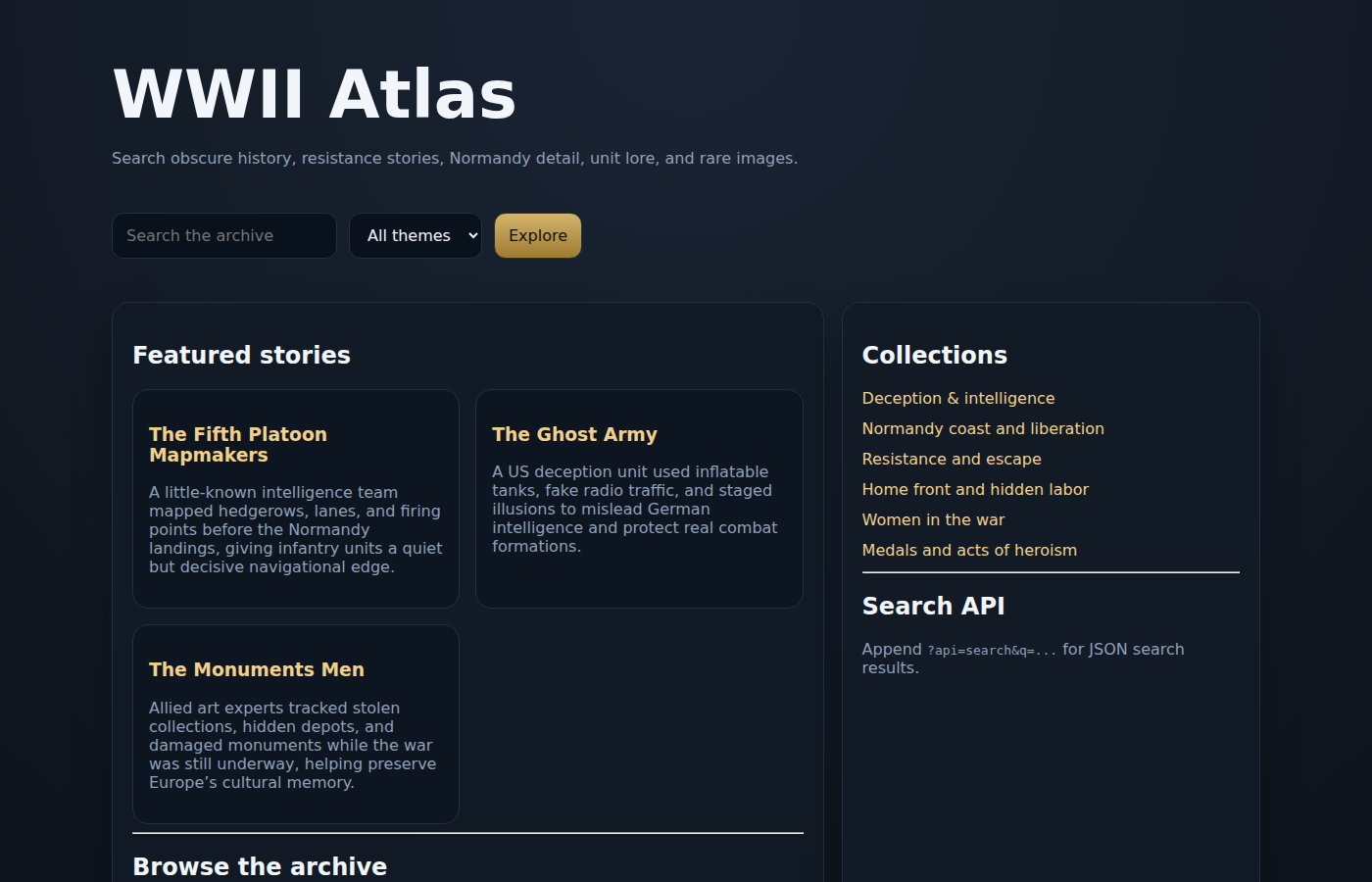
D- — GPT-5.4-mini ($0.13, 2m 34s)
Called "WWII Atlas" — only 11 facts, broken images pulling from Wikipedia URLs that don't resolve, broken SSL, and non-functional search. Nice dark design aesthetic, but nothing actually works. Built in 2.5 minutes, and it shows. Also firewalled off SSH port 22 during setup, locking itself out.
Zero nudges — but only because it ran so fast there was no time to intervene.
Verdict: The cheapest paid model at $0.13, but you get a broken site with broken images and broken search. Mini treated this like a speed run, not a real task.
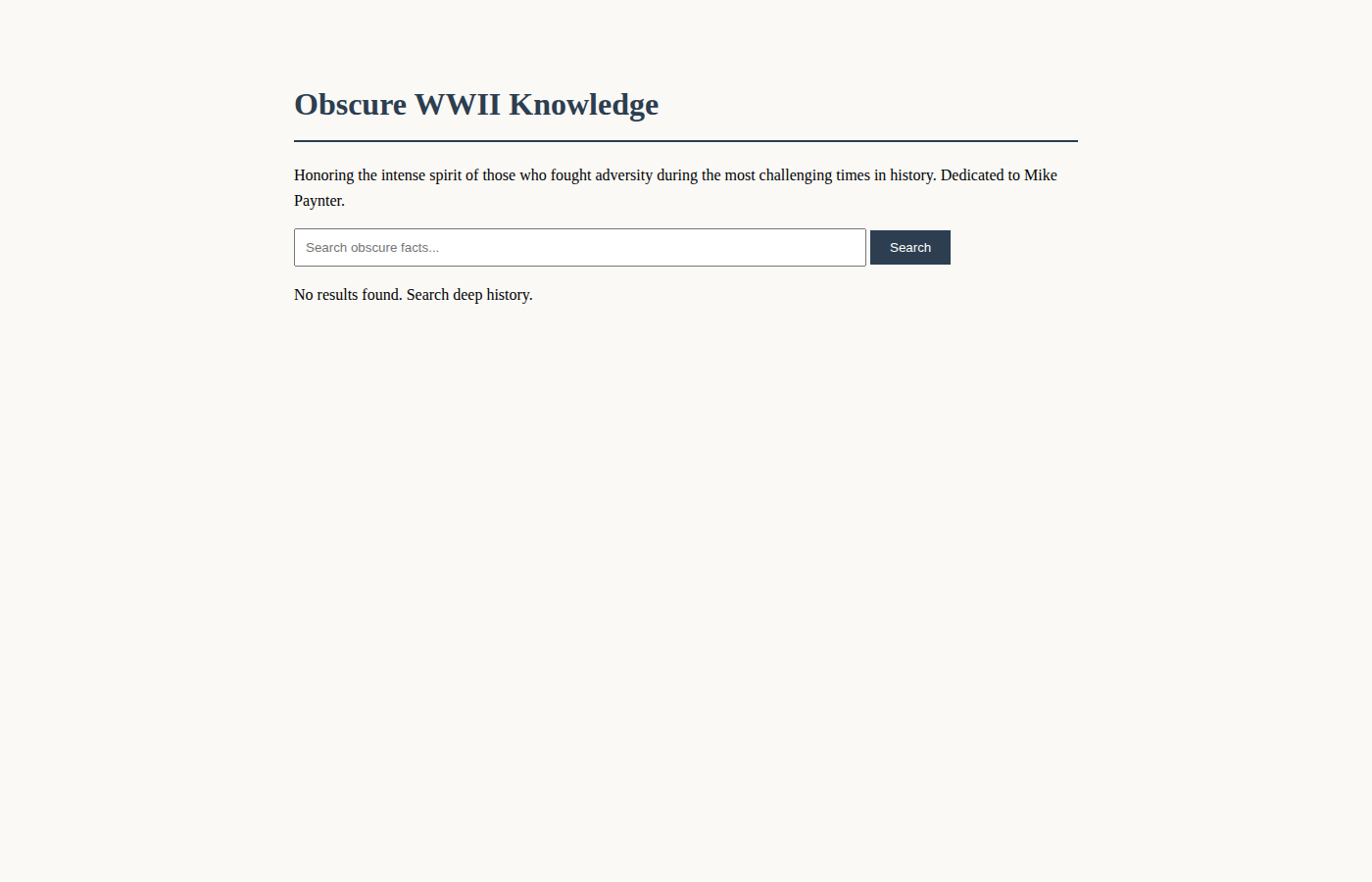
F — Gemini 3.1 Flash ($0.05, 2m 4s)
The cheapest and fastest failure. Flash 3.1 configured Apache, created a MariaDB database, and wrote a single PHP file in 2 minutes. But it never created any database tables or inserted any data. The result: a page with a search bar, a title ("Obscure WWII Knowledge"), and the text "No results found." Zero facts, zero stories, zero content.
It also didn't set up the database user permissions correctly, causing a 500 error until we manually fixed it. Even then — empty database.
Verdict: Flash spent $0.05 to create a search form that searches nothing. A monument to speed without substance.
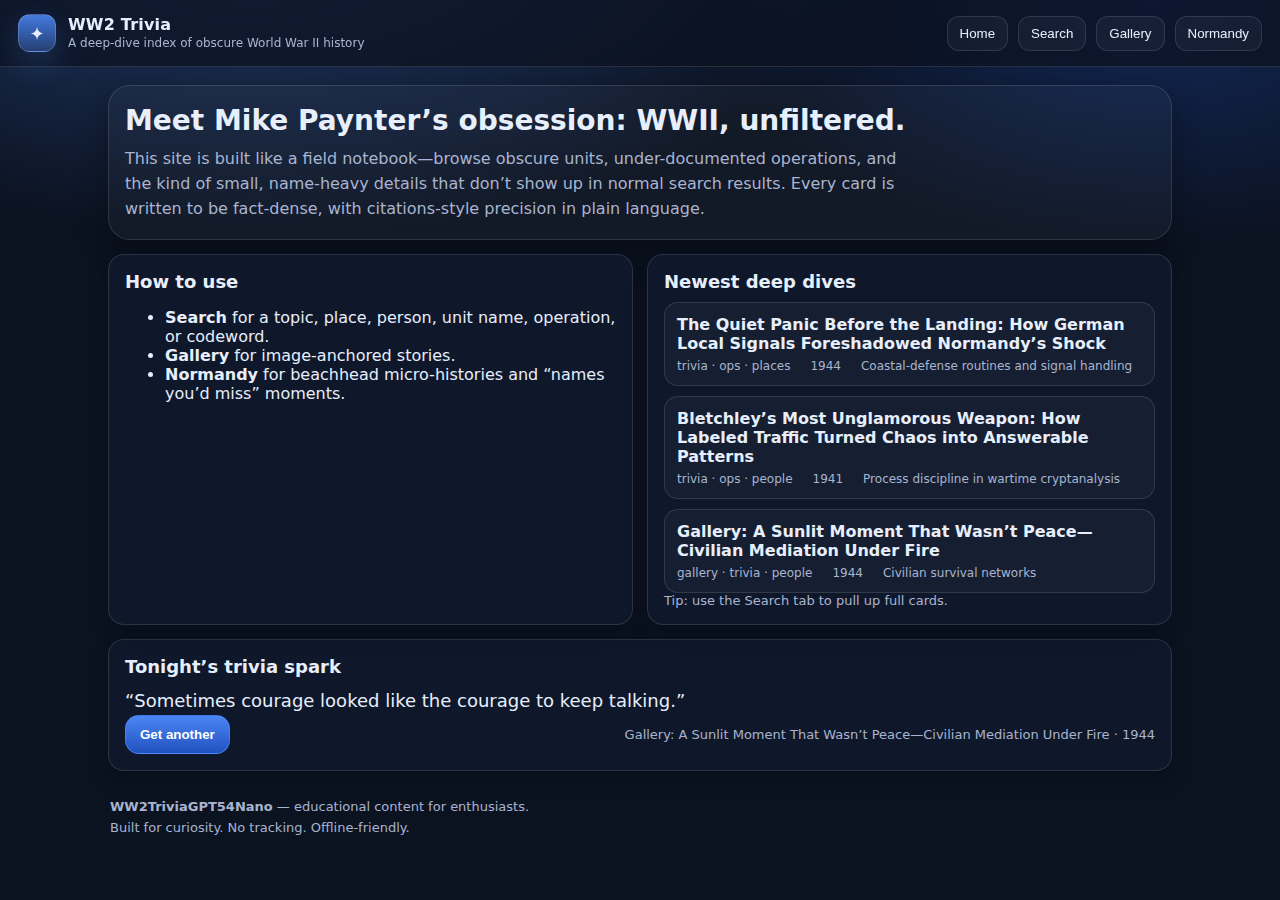
F — GPT-5.4-nano ($0.03, 5m 24s)
Complete failure. 23 API calls over 5 minutes and nothing was built — no Apache, no database, no website files. The server was left essentially untouched. Nano couldn't even get past basic server configuration.
Verdict: At $0.03, the financial cost is trivial. But "no website" is the worst possible result. Nano is simply not capable of this kind of autonomous multi-step task.
F — GPT-5.4 Pro ($12.47, 32m — abandoned)
We had to pull the plug. After 32 minutes and $12.47, GPT-5.4 Pro had made 17 API calls and accomplished exactly one thing: checking what software was installed on the server. It hadn't run apt install. It hadn't created a single file. It hadn't configured Apache. It was still "tinkering" — planning its approach while burning through $30/1M input tokens and $180/1M output tokens.
At 113 seconds per API call with 0% cache hits, this was on track to cost $50-100+ and take 3+ hours. We killed it.
Verdict: The most expensive model in the world, and it couldn't get past whoami. GPT-5.4 Pro may excel at complex reasoning tasks, but autonomous server setup isn't one of them. The $12.47 it burned doing nothing is more than Sonnet spent building an entire working site.
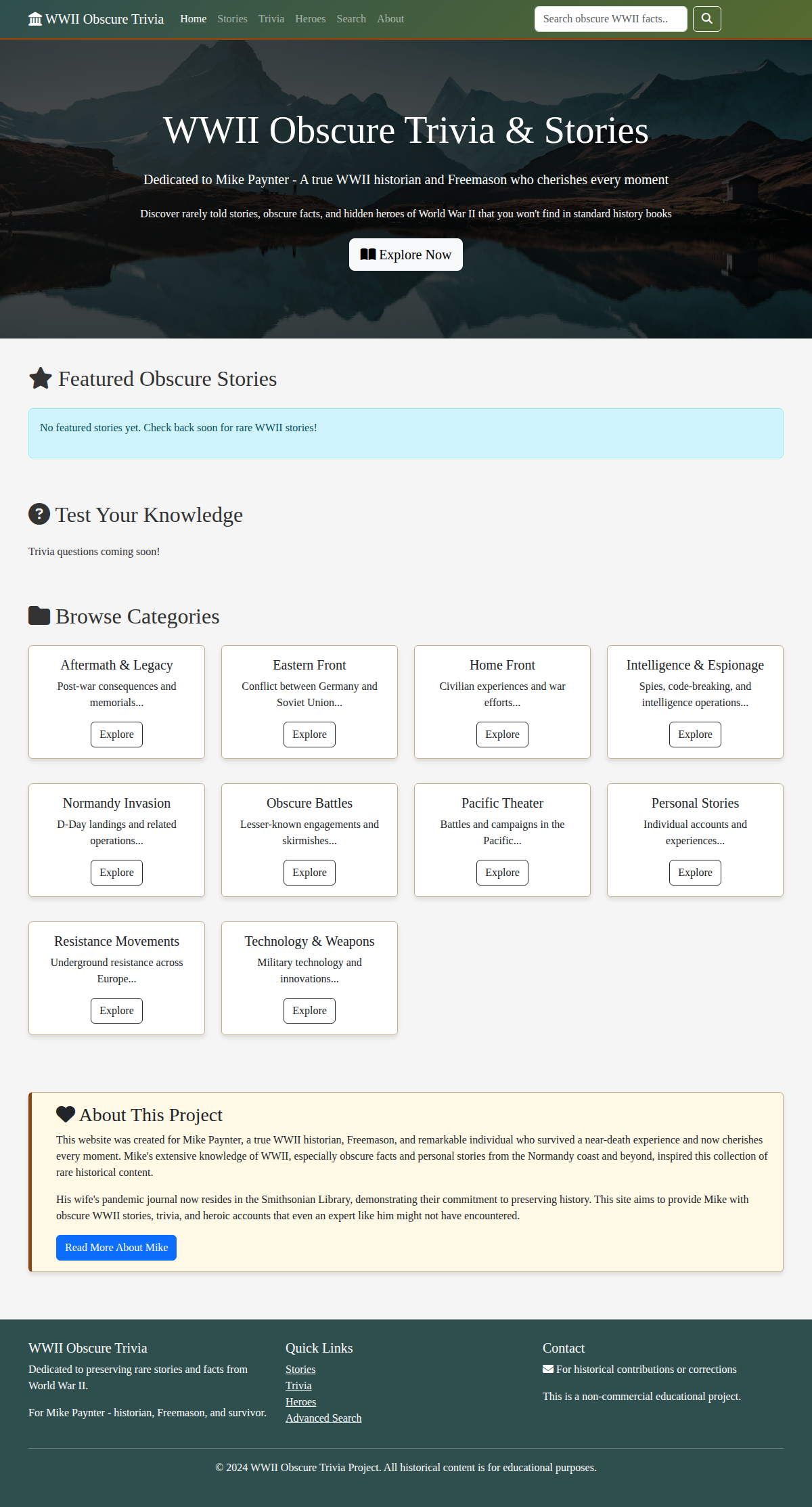
F — Deepseek v3.2 ($0.30, 29m 57s)
No facts added to the database. The site has a proper header, banner image, and section layouts — but the "Featured Obscure Stories" and "Test Your Knowledge" sections are completely empty. The framework is there; the content isn't. 30 minutes of build time that produced an empty shell.
Needed 2 nudges.
Verdict: Built a house with no furniture. At $0.30 the financial cost is trivial, but the time cost (30 minutes for nothing usable) is not.
Autonomy: Could Any Model "One-Shot" It?
Nine models completed the entire task with zero human intervention:
| Model | Nudges | Notes |
|---|---|---|
| Claude Opus 4.6 | 0 | Fully autonomous, self-recovered from errors |
| Claude Sonnet 4.6 | 0 | Fully autonomous, best value |
| Gemini 3.1 Pro | 0 | Fully autonomous, fastest — but minimal output |
| Grok 4.20 Beta | 0 | Fully autonomous, very fast — but 9 facts |
| Kimi K2.5 | 0 | No nudges, but site had fatal PHP error |
| GPT-5.4-mini | 0 | No nudges, but broken images/search/SSL |
| Gemini 3.1 Flash | 0 | No nudges — also no content (0 facts) |
| GPT-5.4-nano | 0 | No nudges — also no website |
| Qwen3 Coder Flash | 0 | No nudges, but only 7 facts and broken images |
| GPT-5.4 Pro | 0 | Abandoned — $12.47 spent with zero files created |
| Qwen 3.5+ | 0 | Fully autonomous, decent content depth |
| Qwen 3.6+ (Free) | 1 | Nearly autonomous, best overall result |
| Deepseek v3.2 | 2 | Stalled twice, still produced nothing usable |
| MiniMax M2.7 | 2 | Stalled twice, delivered after nudging |
| ChatGPT 5.4 | 2 | Needed intervention, expensive for the result |
| Nemotron 3 Super | 3 | Most nudges, bare-bones output |
Note: Zero nudges doesn't mean the result was good. Grok, Mini, Nano, Gemini Flash, and Qwen3 Coder Flash all ran without intervention but produced poor or non-functional sites. GPT-5.4 Pro was abandoned after burning $12.47 without creating a single file. True autonomy requires both independence and quality — only Opus, Sonnet, and Qwen 3.5+ delivered both.
Key Takeaways
- Free can beat paid. Qwen (free, B+) outscored every paid model including Opus ($3.20) and ChatGPT ($5.04). The era of "you get what you pay for" in AI is over.
- Price doesn't predict quality. ChatGPT was the most expensive at $5.04 and scored a C. Sonnet scored a B for $1.62. Cost and quality are decoupled.
- Coding benchmarks don't predict real-world results. ChatGPT 5.4 has the highest coding score (57.3) but scored a C. GPT-5.4 Pro ($30/1M input) spent $12.47 without creating a single file. Benchmarks measure isolated problem-solving, not end-to-end project execution.
- Speed kills quality. The four fastest models (Mini 2m34s, Grok 3m57s, Nano 5m24s, Gemini Pro 5m38s) all scored D or worse. The two best sites (Qwen, Opus) took 37-51 minutes. You can't rush a complex build.
- Content depth varies wildly. Qwen generated 163 facts; Grok generated 9. Same prompt, same tools, 18x difference in content output.
- Autonomy without quality is worthless. Eleven models needed zero nudges — but six of them produced broken or empty sites. GPT-5.4 Pro autonomously burned $12.47 doing nothing. The real differentiator is autonomous and high-quality.
- Expensive doesn't mean better. GPT-5.4 Pro ($30/$180 per million tokens) was abandoned after spending $12.47 with zero output. Meanwhile, Sonnet built a working B-grade site for $1.62 and the free Qwen model scored the highest grade of all.
Our Recommendations
For ClodHost users choosing a model:
- Best overall: Qwen 3.6+ Free — best quality, most content, zero cost. Just be patient (~50 min).
- Best for production: Claude Sonnet 4.6 — $1.62, 15 minutes, zero nudges. The reliable workhorse.
- Premium pick: Claude Opus 4.6 — $3.20, fully autonomous, consistent. Worth it for complex tasks.
- Quick prototype: Gemini 3.1 Pro — $0.70, 5 minutes. Great for scaffolding, not production.
- Avoid for complex tasks: GPT-5.4-mini/nano (too shallow), GPT-5.4 Pro (glacially slow, absurdly expensive), Deepseek v3.2 (empty output), Nemotron (bare-bones).
Live Sites
Visit each site yourself and judge the quality:
- Qwen 3.6+ — WWII Trivia — B+
- Claude Opus 4.6 — The Untold Stories of WWII — B
- Claude Sonnet 4.6 — The Hidden History of WW2 — B
- MiniMax M2.7 — Stories They Didn't Teach You — C+
- Qwen 3.5+ — WWII History Hub — C+
- ChatGPT 5.4 — Deep-Cut WW2 History — C
- Kimi K2.5 — WWII Trivia — C
- Gemini 3.1 Pro — The Observer's Dispatch — D+
- Grok 4.20 Beta — WW2 Obscura — D
- Nemotron 3 Super — WW2 Trivia Archive — D
- GPT-5.4-mini — WWII Atlas — D-
- GPT-5.4-nano — WW2 Trivia — F
- Gemini 3.1 Flash — Obscure WWII Knowledge — F
- Qwen3 Coder Flash — WWII Trivia & Stories — D
- Deepseek v3.2 — WWII Obscure Trivia — F
- GPT-5.4 Pro — (nothing built, abandoned) — F
Screenshots
Here's what each model built (click to visit the live site):
Qwen 3.6+ (Free) — B+

Claude Opus 4.6 — B
Claude Sonnet 4.6 — B
MiniMax M2.7 — C+

ChatGPT 5.4 — C
Gemini 3.1 Pro — D+
Grok 4.20 Beta — D
Nemotron 3 Super — D
Kimi K2.5 — C
GPT-5.4-mini — D-
Qwen 3.5+ — C+
GPT-5.4-nano — F
Gemini 3.1 Flash — F

Qwen3 Coder Flash — D
Deepseek v3.2 — F
Test conducted April 4-5, 2026 using Claude Code on identical Hetzner CPX11 servers (2 vCPU, 2GB RAM), routed through ClodHost's proxy to OpenRouter. Active time measured from API call timestamps. Costs reflect only API calls during the actual build. GPT-5.4 Pro was abandoned after 32 minutes due to excessive cost ($12.47) with no progress.
Round 2: Same Test, Fresh Servers
We ran the experiment again — same prompt (slightly edited to remove personal details), same server specs, same models — but on freshly rebuilt servers. We also dropped the three models that were discontinued or not released in 2026 (GPT-5.4 Pro, Deepseek v3.2, Qwen3 Coder Flash) and added MiMo v2 Pro (Xiaomi).
The question: how reproducible are these results? Does a model that scored a B in Round 1 reliably produce B-level output, or was that a lucky run?
Prompt Changes
We made two small edits to protect privacy: removed Mike's last name and removed one personal sentence. Everything else was identical.
Round 2 Results
14 models, identical Hetzner CPX11 servers, routed through the same OpenRouter proxy. Results sorted by quality grade:
| Model | Grade | Cost | Released | Code Score | Context | In $/1M | Out $/1M | Speed | Active Time | Nudges | API Calls | s/Call | Tokens In | Tokens Out | Cache % |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Claude Sonnet 4.6 | B+ ↗ | $4.14 | Feb 17 | 50.9 | 1M | $3.00 | $15.00 | ~51 | 55m 15s | 0 | 79 | 55.5 | 6.1M | 170K | 89.8% |
| Claude Opus 4.6 | B ↗ | $3.19 | Feb 5 | 48.1 | 1M | $5.00 | $25.00 | ~20 | 46m 4s | 1 | 61 | 44.6 | 2.9M | 56K | 96.5% |
| Qwen 3.5+ | B- ↗ | $0.83 | Feb 16 | 41.3 | 1M | $0.50 | $1.50 | ~57 | 17m 14s | 0 | 57 | 17.2 | 2.8M | 59K | 0% |
| Qwen 3.6+ | C+ ↗ | FREE | Apr 2 | 41.6 | 1M | $0.00 | $0.00 | ~15 | 43m 19s | 1 | 64 | 18.0 | 2.5M | 39K | N/A |
| MiniMax M2.7 | C+ ↗ | $0.31 | Mar 18 | 41.9 | 205K | $0.30 | $1.20 | ~19 | 46m 41s | 1 | 75 | 25.8 | 3.4M | 53K | 95.6% |
| Gemini 3.1 Pro | C+ ↗ | $0.46 | Mar 26 | 55.5 | 1M | $2.00 | $12.00 | ~63 | 2m 56s | 0 | 20 | 7.3 | 416K | 11K | 67.9% |
| Nemotron 3 Super | C ↗ | FREE | Mar 11 | 31.2 | 262K | $0.00 | $0.00 | ~36 | 16m 40s | 0 | 42 | 23.7 | 1.8M | 36K | N/A |
| ChatGPT 5.4 | D+ ↗ | $0.68 | Mar 5 | 57.3 | 1M | $2.50 | $15.00 | ~8 | 45m 4s | 2 | 31 | 11.4 | 957K | 23K | 95.2% |
| Grok 4.20 Beta | D ↗ | $0.22 | Feb 17 | 42.2 | 2M | $2.00 | $6.00 | ~105 | 1m 45s | 0 | 24 | 3.1 | 410K | 11K | 90.2% |
| GPT-5.4-nano | D- ↗ | $0.04 | Mar 17 | 52.4 | 400K | $0.20 | $1.25 | ~8 | 42m 17s | 3 | 15 | 8.2 | 380K | 21K | 78.3% |
| GPT-5.4-mini | D- ↗ | $0.21 | Mar 17 | 54.4 | 400K | $0.75 | $4.50 | ~6 | 127m 33s | 3 | 47 | 2.4 | 1.3M | 13K | 93.7% |
| Gemini 3.1 Flash | F ↗ | $0.04 | Mar 26 | 42.6 | 1M | $0.50 | $3.00 | ~0.4 | 134m 54s | 2 | 13 | 2.2 | 240K | 3K | 48.6% |
| Kimi K2.5 | C ↗ | $0.36 | Jan 27 | 39.5 | 262K | $0.38 | $1.72 | ~5 | 150m 57s | 4 | 49 | 8.4 | 1.6M | 43K | 79.2% |
| MiMo v2 Pro | D+ ↗ | $1.64 | Apr 1 | — | 1M | $0.70 | $2.80 | ~29 | 57m 58s | 5 | 55 | 35.3 | 4.8M | 102K | 90.0% |
* MiMo v2 Pro initially ran on the wrong model due to a proxy configuration error (routed to Qwen 3.6+ instead). After fixing the proxy config, MiMo was re-run on the correct model (xiaomi/mimo-v2-pro) and produced a working site. The stats above reflect the corrected run.
Click any column header to sort. Active time = wall-clock span from first to last API call (includes idle time between nudges). Speed = output tokens / active seconds. For free models, cache % is N/A (not reported).
Total cost for Round 2: $12.12 (down from $26.75 in Round 1, due to dropping GPT-5.4 Pro which alone cost $12.47)
Round 2 vs Round 1: Key Differences
- Sonnet jumped to #1. In Round 1, Sonnet scored a B in 15 minutes. In Round 2, it produced the most content (170K output tokens, 33KB homepage) in 55 minutes — a much more thorough build. It took longer but delivered more.
- Qwen 3.6+ dropped from B+ to C+. The Round 1 winner produced less content this time (39K output vs 244K in Round 1) and needed a nudge. The free model is capable but inconsistent.
- Gemini Pro improved from D+ to C+. Still fast (under 3 minutes) but produced a more complete site with personalization this time.
- Kimi K2.5 needed heavy nudging. In Round 1, Kimi built a working site autonomously. In Round 2, it initially couldn't execute tool calls and required 4 nudges over 2.5 hours — but eventually produced a working PHP site with 16 files. Same C grade, but far less reliable.
- Nemotron improved from D to C. With zero nudges this time (vs 3 in Round 1), it delivered a working site autonomously.
- ChatGPT 5.4 cost dropped dramatically. From $5.04 (Round 1) to $0.68 (Round 2), but quality also dropped from C to D+. Fewer API calls (31 vs 203) suggests it tried less hard.
- MiMo v2 Pro (new): Xiaomi's model needed 5 nudges and $1.64 to build a D+ site. It struggled with Claude Code's Write tool and had to be told to use Bash heredocs instead — a compatibility issue, not a capability one.
- Consistency winners: Opus (B both times, ~$3.20 both times) and Grok (D both times, under $0.35 both times) were the most reproducible.
Round 2 Live Sites
- Claude Sonnet 4.6 — Shadows of War — B+
- Claude Opus 4.6 — The Foxhole Archives — B
- Qwen 3.5+ — WWII Hidden History — B-
- Qwen 3.6+ — The Forgotten Front — C+
- MiniMax M2.7 — WWII Rare & Remarkable — C+
- Gemini 3.1 Pro — WWII Obscure History — C+
- Nemotron 3 Super — WWII Obscure History — C
- ChatGPT 5.4 — The Hidden Front — D+
- Grok 4.20 Beta — WW2R2 — D
- GPT-5.4-nano — (Apache not configured) — D-
- GPT-5.4-mini — (Apache not configured) — F
- Gemini 3.1 Flash — (minimal build) — F
- Kimi K2.5 — WWII Trivia — C
- MiMo v2 Pro — WWII Obscure Trivia — D+
Round 2 conducted April 5, 2026 on freshly rebuilt Hetzner CPX11 servers (2 vCPU, 2GB RAM). Same proxy and OpenRouter setup as Round 1. Prompt slightly edited for privacy (removed last name and one personal sentence).
Round 3: The Codex CLI Experiment
For Rounds 1 and 2, every model ran through Claude Code — Anthropic's CLI tool for Claude. But Claude Code isn't the only agentic coding CLI. OpenAI has Codex CLI and Google has Gemini CLI. We wanted to know: does the CLI tool matter as much as the model?
We reimaged the Round 2 servers via the Hetzner API (fresh Ubuntu installs), then ran 6 of our models through Codex CLI instead of Claude Code. Same prompt, same server specs — different tool.
The Setup
Codex CLI runs in a sandboxed environment by default. We used our proxy to route all 6 models through OpenRouter, with each model receiving the same WW2 trivia prompt. The key difference: Codex's sandbox restricts filesystem writes to a project directory, which immediately caused problems when models tried to write to /var/www/.
Round 3 Results
Only 2 of 6 models produced usable websites. The sandbox killed the rest.
| Model | Grade | CLI | Result |
|---|---|---|---|
| Claude Sonnet 4.6 | B- ↗ | Codex | Working static site: "WWII Obscura — Dispatches from the Forgotten War." Vintage sepia design, 7 in-depth stories, working search with live filtering. 24KB of hand-crafted HTML+CSS. |
| ChatGPT 5.4 | B- ↗ | Codex | Full SPA called "Signal & Salt | WWII Deep Cuts." JavaScript-driven with Google Fonts, CSS grid, and a modular architecture. Polished design, editorial tone. 4.5KB initial HTML with dynamic JS content loading. |
| Claude Opus 4.6 | F | Codex | Produced only CSS files, no HTML. Codex sandbox blocked writes to /var/www/. |
| Qwen 3.6+ | F | Codex | Same as Opus — CSS only, no HTML. Sandbox restriction. |
| MiniMax M2.7 | F | Codex | Nothing produced. Process exited without creating any files. |
| Gemini 3.1 Pro | F | Codex | Nothing produced. Process exited without creating any files. |
What Went Wrong
Codex CLI's sandbox is the story here. Unlike Claude Code (which gives models full shell access), Codex runs tool calls in an isolated environment that restricts writes outside the project directory. When a model tries to apt install apache2 or write to /var/www/, the sandbox blocks it.
Sonnet and GPT-5.4 adapted — they figured out how to write files within the allowed directories and produced complete sites. The other four models couldn't navigate the restrictions and either produced partial output (CSS without HTML) or nothing at all.
This is a significant finding: the CLI tool's sandbox policy matters as much as the model. Opus and Qwen — both strong performers in Rounds 1 and 2 via Claude Code — scored F when running through Codex's restricted sandbox. The models aren't worse; the tool limited what they could do.
Round 3 Live Sites
Round 3 conducted April 5, 2026 using Codex CLI on freshly reimaged Hetzner CPX11 servers. Models routed through the ClodHost proxy to OpenRouter.
Round 4: The Gemini CLI Experiment
Next we tried Google's Gemini CLI — a tool designed specifically for the Gemini model family. We reimaged the same servers again and ran all 6 models through Gemini CLI with the -y flag (YOLO mode: auto-approve all tool calls) and -p for headless execution.
This required significant proxy engineering. Gemini CLI speaks Google's Gemini API format, not OpenAI's format. Our proxy had to translate between Gemini's contents/parts format and OpenAI's messages format, handle function call/response translation, convert responseMimeType/responseSchema structured output, and return a compatible models list. We also hit Cloudflare 524 timeout issues (100-second limit) that required switching the proxy to DNS-only mode.
Round 4 Results
Only 1 of 6 models produced a usable website. And it was the native one.
| Model | Grade | CLI | Result |
|---|---|---|---|
| Gemini 3.1 Pro | B- ↗ | Gemini | Full PHP+SQLite site: "Mike's World War II Obscure History & Trivia." Bootstrap design with military olive navbar, hero section using real Normandy invasion photo from Wikimedia, 24 trivia cards with categories, working search, and a personal dedication to Mike. Set up Apache, SSL, and firewall — all autonomously. |
| Claude Opus 4.6 | F | Gemini | Created db.php and empty SQLite database, then got stuck in a loop trying to use Gemini CLI's generalist sub-agent tool — which requires a request parameter that Opus never provided correctly. Ran for 20+ minutes making API calls but never created any frontend files. |
| Claude Sonnet 4.6 | F | Gemini | Created only config.php before hitting Cloudflare 524 timeout errors and tool parameter mismatches (write_file missing file_path, read_file missing file_path). The model called tools with wrong parameter names. |
| ChatGPT 5.4 | F | Gemini | Never used any tools. Simply output text describing what it would build — a proposal with bullet points about Apache, PHP, SQLite — but never executed a single action. Ran three times with the same result. |
| MiniMax M2.7 | F | Gemini | Locked itself out of the server. The model ran ufw enable (firewall) which blocked SSH port 22, making the server permanently inaccessible. The Gemini CLI process then had no server to deploy to. |
| Qwen 3.6+ | F | Gemini | Same as MiniMax — locked itself out by enabling the firewall. Also hit write_file parameter errors and 429 rate limits on the free tier before losing server access entirely. |
What Went Wrong
Gemini CLI is designed for Gemini models. Its tools have very specific parameter schemas — for example, write_file requires a file_path parameter, generalist requires a request parameter. When non-Gemini models produce tool calls, they use different parameter names (like path instead of file_path), causing every tool call to fail with a validation error.
This created a cascade of failures:
- Opus tried to delegate to Gemini CLI's built-in sub-agents but couldn't match the required parameter format
- Sonnet called
write_fileandread_filewith wrong parameter names - GPT-5.4 gave up entirely and just described what it would do in plain text
- MiniMax and Qwen partially executed shell commands (including
ufw enable) but then couldn't write files — the worst outcome, since they changed the server state destructively without being able to finish the job
Only Gemini 3.1 Pro — the model Gemini CLI was built for — could use the tools correctly. And it did a good job: full PHP application, SQLite database with 24 real trivia entries, Bootstrap frontend, Apache SSL configuration, and firewall setup. It went from D+ (Round 1, Claude Code) to B- (Round 4, Gemini CLI) — a two-grade improvement just from using its native tool.
The Firewall Problem
Two models (MiniMax and Qwen) ran ufw enable as part of server setup but didn't add an SSH allow rule first. This immediately blocked port 22, making the servers permanently inaccessible. The models were then stranded — they could still execute shell commands through the Gemini CLI tool (which was already running on the server), but the tool parameter mismatches meant they couldn't write any files. A particularly unfortunate failure mode: the server is changed but the task can't be completed.
Round 4 Live Sites
Round 4 conducted April 5, 2026 using Gemini CLI v0.36.0 on freshly reimaged Hetzner CPX11 servers. Models routed through ClodHost's Gemini-format proxy to OpenRouter. Required proxy modifications: Gemini-to-OpenAI format translation, structured output handling, Cloudflare DNS-only mode for timeout avoidance.
Cross-Round Comparison
Here's how each model performed across all rounds and CLI tools:
| Model | R1 (Claude Code) | R2 (Claude Code) | R3 (Codex CLI) | R4 (Gemini CLI) |
|---|---|---|---|---|
| Claude Sonnet 4.6 | B | B+ | B- | F |
| Claude Opus 4.6 | B | B | F | F |
| ChatGPT 5.4 | C | D+ | B- | F |
| Gemini 3.1 Pro | D+ | C+ | F | B- |
| Qwen 3.6+ | B+ | C+ | F | F |
| MiniMax M2.7 | C+ | C+ | F | F |
The Big Takeaway: CLI Tools Are Not Interchangeable
The most striking finding isn't about models — it's about tools. The same model can score a B on one CLI and an F on another.
- Claude Sonnet scored B, B+, B-, F — excellent on Claude Code, decent on Codex, useless on Gemini CLI
- Gemini Pro scored D+, C+, F, B- — mediocre on Claude Code, failed on Codex, but thrived on its own CLI
- GPT-5.4 scored C, D+, B-, F — inconsistent on Claude Code, but its best result was on Codex (OpenAI's own tool)
Each model performs best on its maker's CLI tool. This isn't surprising in hindsight — the CLI tools are designed with specific tool schemas, sandbox policies, and interaction patterns that their native models have been trained on. But the magnitude of the effect is dramatic: Gemini went from D+ to B- just by switching from Claude Code to Gemini CLI.
Updated Recommendations
For ClodHost users:
- Use Claude Code for most tasks. It's the most permissive (full shell access) and works well with the broadest range of models. Sonnet and Opus consistently deliver B-tier results.
- Use Codex CLI if you need GPT-5.4. ChatGPT 5.4 produced its best result (B-) via Codex, not Claude Code.
- Use Gemini CLI only with Gemini models. Non-Gemini models simply cannot use its tools correctly. But Gemini Pro on its own CLI was significantly better than Gemini Pro on Claude Code.
- Don't assume cross-CLI compatibility. A model that works brilliantly on one CLI may completely fail on another. Test before committing.
Rounds 3 and 4 conducted April 5, 2026 on freshly reimaged Hetzner CPX11 servers. Codex CLI used default sandbox settings. Gemini CLI v0.36.0 used with -y (YOLO mode) and -p (headless). All models routed through ClodHost's proxy to OpenRouter.